



Federation Framework Overview
Note
-
The term relationship is equivalent to the term link.
-
The term CI is equivalent to the term object.
-
A graph is a collection of nodes and links.
The Federation Framework functionality uses an API to retrieve information from federated sources. The Federation Framework provides three main capabilities:
-
Federation on the fly. All queries are run over original data repositories and results are built on the fly in the
-
Population. Populates data (topological data and CI properties) to the
-
Data Push. Pushes data (topological data and CI properties) from the local
All action types require an adapter for each data repository, which can provide the specific capabilities of the data repository and retrieve and/or update the required data. Every request to the data repository is made through its adapter.
Federation on the Fly
Federated TQL queries enables data retrieval from any external data repository without replicating its data.
A federated TQL query uses adapters that represent external data repositories, to create appropriate external relationships between CIs from different external data repositories and the
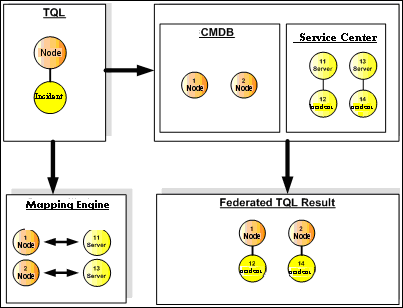
Example of Federation-on-the-Fly Flow:
-
The Federation Framework splits a federated TQL query into several subgraphs, where all nodes in a subgraph refer to the same data repository. Each subgraph is connected to the other subgraphs by a virtual relationship (but itself contains no virtual relationships).

-
After the federated TQL query is split into subgraphs, the Federation Framework calculates each subgraph's topology and connects two appropriate subgraphs by creating virtual relationships between the appropriate nodes.
- After the federated TQL topology is calculated, the Federation Framework retrieves a layout for the topology result.

Data Push
You use the data push flow to synchronize data from your current local
In data push, data repositories are divided into two categories: source (local
The data push process flow includes the following steps:
-
Retrieving the topology result with signatures from the source data repository.
-
Comparing the new results with the previous results.
-
Retrieving a full layout (that is, all CI properties) of CIs and relationships, for changed results only.
-
Updating the target data repository with the received full layout of CIs and relationships. If any CIs or relationships are deleted in the source data repository and the query is exclusive, the replication process removes the CIs or relationships in the target data repository as well.
The
Population
You use the population flow to populate the
The flow always uses one 'source' data source to retrieve the data, and pushes the retrieved data to the Probe in a similar process to the flow of a discovery job.
To implement a new adapter for population flows, you only have to implement the source adapter, since the Data Flow Probe acts as the target.
The adapter in the population flow is executed on the Probe. Debugging and logging should be done on the Probe and not on the
The population flow is based on query names, that is, data is synchronized between the source data repository and the Data Flow Probe, and is retrieved by a query name in the source data repository. For example, in
Each job can be defined as an exclusive job. This means that the CIs and relationships in the job results are unique in the local
-
Retrieves the topology result with signatures from the source data repository.
-
Compares the new results with the previous results.
-
Retrieves a full layout (that is, all CI properties) of CIs and relationships, for changed results only.
-
Updates the target data repository with the received full layout of CIs and relationships. If any CIs or relationships are deleted in the source data repository and the query is exclusive, the replication process removes the CIs or relationships in the target data repository as well.
-
Retrieves the topology result that occurred since the last date given.
-
Retrieves a full layout (that is, all CI properties) of CIs and relationships, for changed results only.
-
Updates the target data repository with the received full layout of CIs and relationships. If any CIs or relationships are deleted in the source data repository and the query is exclusive, the replication process removes the CIs or relationships in the target data repository as well.
-
Retrieves the full topology with requested layout result.
-
Uses the topology chunk mechanism to retrieve the data in chunks.
-
The probe filters out any data that was already brought in earlier runs
-
Updates the target data repository with the received layout of CIs and relationships. If any CIs or relationships are deleted in the source data repository and the query is exclusive, the replication process removes the CIs or relationships in the target data repository as well.
PopulateChangesDataAdapter Flow
-
Retrieves the topology with requested layout result that has changes since the last run.
-
Uses the topology chunk mechanism to retrieve the data in chunks.
-
The probe filters out any data that was already brought in earlier runs (including this flow).
-
Updates the target data repository with the received layout of CIs and relationships. If any CIs or relationships are deleted in the source data repository and the query is exclusive, the replication process removes the CIs or relationships in the target data repository as well.
Instance-Based Population Flow
If the adapter is defined to support an instance-based flow (by means of the <instance-based-data> tag, as described in XML Configuration Tags and Properties), the population engine automatically finds removed CIs inside the instance and removes them from the UCMDB (assuming deletion is allowed for the specific population job). Each instance must have a Root CI, marked in the TQL definition with the name Root. Each time a root CI is passed, its entire instance (all the CIs connected to it) are compared to the last time it was sent to UCMDB, and any CIs that were connected to the root but are now not connected to it are deleted from UCMDB. For the adapter to correctly support instance-based flow, any change to any CI or attribute in the entire instance must trigger a resend of the entire instance to UCMDB.