



Data-In Service - Populating UCMDB
After the Identification service runs, the identified data is merged and inserted into the
Multiple CI Matching
One of the major problems that the Data-In service solves is deciding what to do if the input CI matches multiple
To make this decision, the Data-In service uses match criteria.
The process is as follows:
-
Input CIs are merged with each matching
-
For each pair of CIs resulting from this merge, match (verification and validation) criteria are run.
-
If at least one pair does not pass the match criteria check, the CIs are not merged, and the Data-In service ignores the input CI.
-
If all pairs pass the match criteria check, the CIs are merged.
Note The CIs are merged by the Merge service.
-
For examples of multiple CI matching, see:
Multithreaded Data-In Service
Starting from UCMDB 10.30, the Data-In service is multithreaded and is capable to scale the speed of inserting data into UCMDB by adjusting the number of allocated threads.
Note By default, the Data-In service uses four allocated threads. For more information about how to adjust the allocated threads of the Data-In service, see How to Modify the Maximum Number of Threads for the Data-In Service.
In previous versions of UCMDB, the Data-In service uses a serial architecture and processes the arriving CIs and their updates in a controlled single-threaded approach. This architecture guarantees the data model consistency but is less efficient.

The multithreaded Data-In service concurrently processes multiple CI buckets on multiprocessor or multi-core systems if these buckets do not carry overlapping CIs.
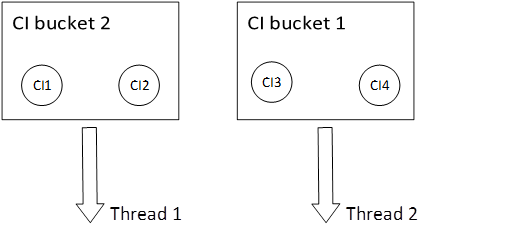
To guarantee the data model consistency, the multithreaded Data-In service processes the CI buckets that carry the same CI information sequentially. In this situation, the multithreaded architecture does not improve the performance of the Data-In service.
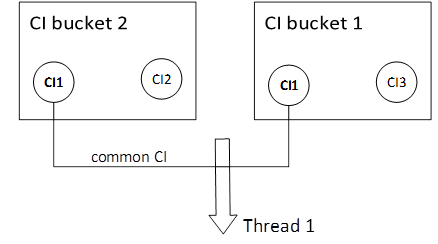
With the multithreaded Data-In service, it is recommended that you consider the following approaches, which can eventually speed up the running jobs and ease the management of UCMDB Data-In:
- Break UCMDB integrations into non-overlapping CI domains
- Set up discovery on different or unrelated CI domains