Multi-tier UCMDB
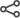
For large enterprise environments there are certain performance considerations in the CMS solution:
- SOLR Search generates load on UCMDB servers and interferes with the throughput of “data in” processes.
- All user interactions are impacted by the “data in” processes – when discovery or integrations are running, the UI-perceived performance is impacted.
- In general, any additional type of operation (examples below) running on the same UCMDB server adds overhead.
Approach
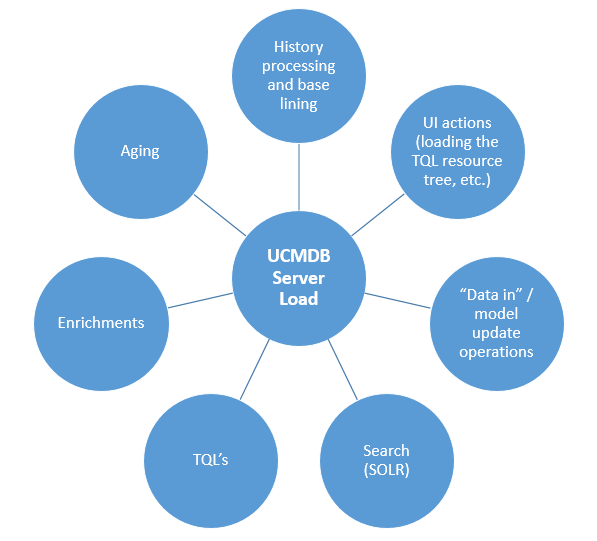
All UCMDB processes can run on a single server at the same time, but this will impact the performance and throughput of the system. After defining which KPIs are essential for the customer, a decision can be made around separating essential operations in different UCMDB servers.
Proposal
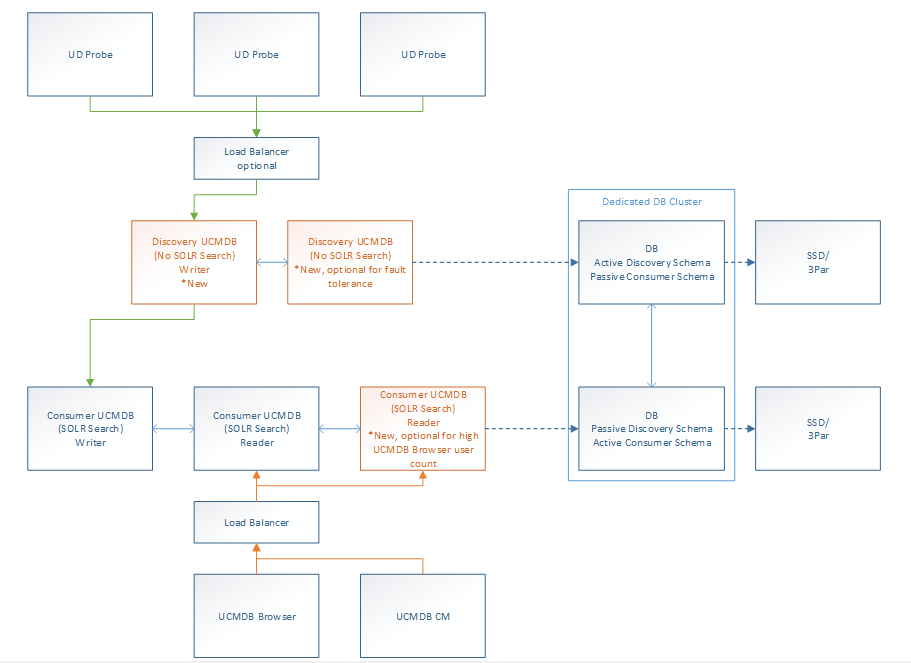
Separate the “data in” process from all data consumption activities. This will improve both the throughput of updating data and the perceived performance for the end users and the consumers of CMS data. The downside is that there is another synchronization step (a scheduled push job) between the Discovery UCMDB and the Consumer UCMDBs that may introduce delays between the point when data is discovered and the point where data is available in the consumer UCMDB.
Separate the “data in” process from the “SOLR Search” operations, which will boost performance for both.
Direct the UCMDB Browser through a load balancer only to the Reader servers of the consumer cluster, further boosting performance of the UCMDB Browser and offloading the consumer Writer server, which has to process data from the Discovery UCMDB.
In general adding the Discovery UCMDB is more valuable than adding more consumer Reader UCMDB servers.
Additional Hardware and Architecture Recommendations
- Increase the current RAM from 24 GB to 32 GB on all the UD Servers.
- Increase the current RAM on Discovery Probes to 16 GB for Enterprise Deployment.
- Try to redistribute the workload so all the probes are utilized (avoid a situation where some probes are underutilized and some are over utilized) – using zone-based discovery.
- Dedicate Probe for integration jobs.
- It is highly recommended that you use physical and dedicated hardware for the UCMDB database in production environments where performance is a concern.
- Assign dedicated resources (such as vCPU, memory, and disk I/O) to a guest operating system that acts as a Probe server.
- Use the high performance storage (such as Micro Focus 3PAR) for UCMDB server and database. In certain scenarios, such as SOLR full indexing, insufficient I/O performance might cause high CPU usage.
- Fine tune discovery schedule.
- Upgrade from Microsoft SQL 2008 to 2012 (or 2014) will increase the CI supportability from 40 million to 60 million.
Required Hardware for Proposed Architecture
| Server | CPU | Memory | Storage |
|---|---|---|---|
| UCMDB Discovery Sever | 16 cores CPU |
32 GB RAM and 48 GB Swap size |
3Par or Fast storage |
| UCMDB Discovery Database | 16 cores CPU |
32 GB RAM and 48 GB Swap size |
3Par or Fast storage |
| UCMDB Reader Sever | 16 cores CPU |
32 GB RAM and 48 GB Swap size |
3Par or Fast storage |
| Discovery Probes (SAM Use Case) | 12 cores CPU |
16 GB RAM and 248 GB Swap size |
300 GB Disk space |
Sample Hardware Recommendation for Enterprise Deployment
| Deployment | CPU | Memory | Linux Swap | Windows Virtual Memory | DB Space | ||||
|---|---|---|---|---|---|---|---|---|---|
| Min | Recommendation | Min | Recommendation | Min | Recommendation | Min | Recommendation | Recommendation | |
| Enterprise | 8 CPUs | 24 CPUs | 24 GB | 32 GB | 24 GB | 32 GB | 32 GB | 48 GB | 300 GB or more |