



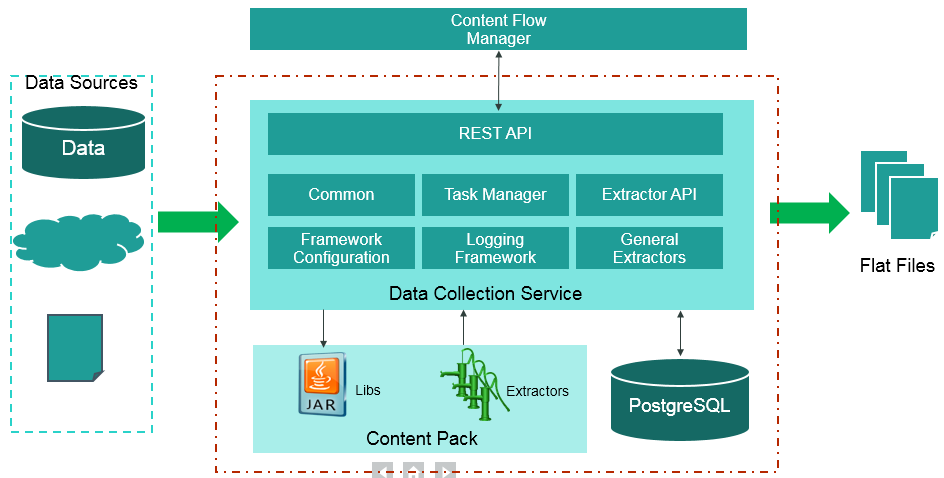
Data Collection Service (DCS) is a standalone service module that is responsible to extract the data from various data sources into flat files according to the relevant extraction and source model that is generated by the IDE. The flat files can then be loaded into the Vertica and run ETL process. The extraction and source model consist of a plugable extractor framework for each data source. The extractor gathers data according to the request it receives from the Content Flow Manager, placing it into a set of relevant .TXT files. Each supported data source has a corresponding extractor (or multiple extractors) that is capable of extracting the relevant data out of the data source. All available extractors for Content Packs use the DCS framework.
-
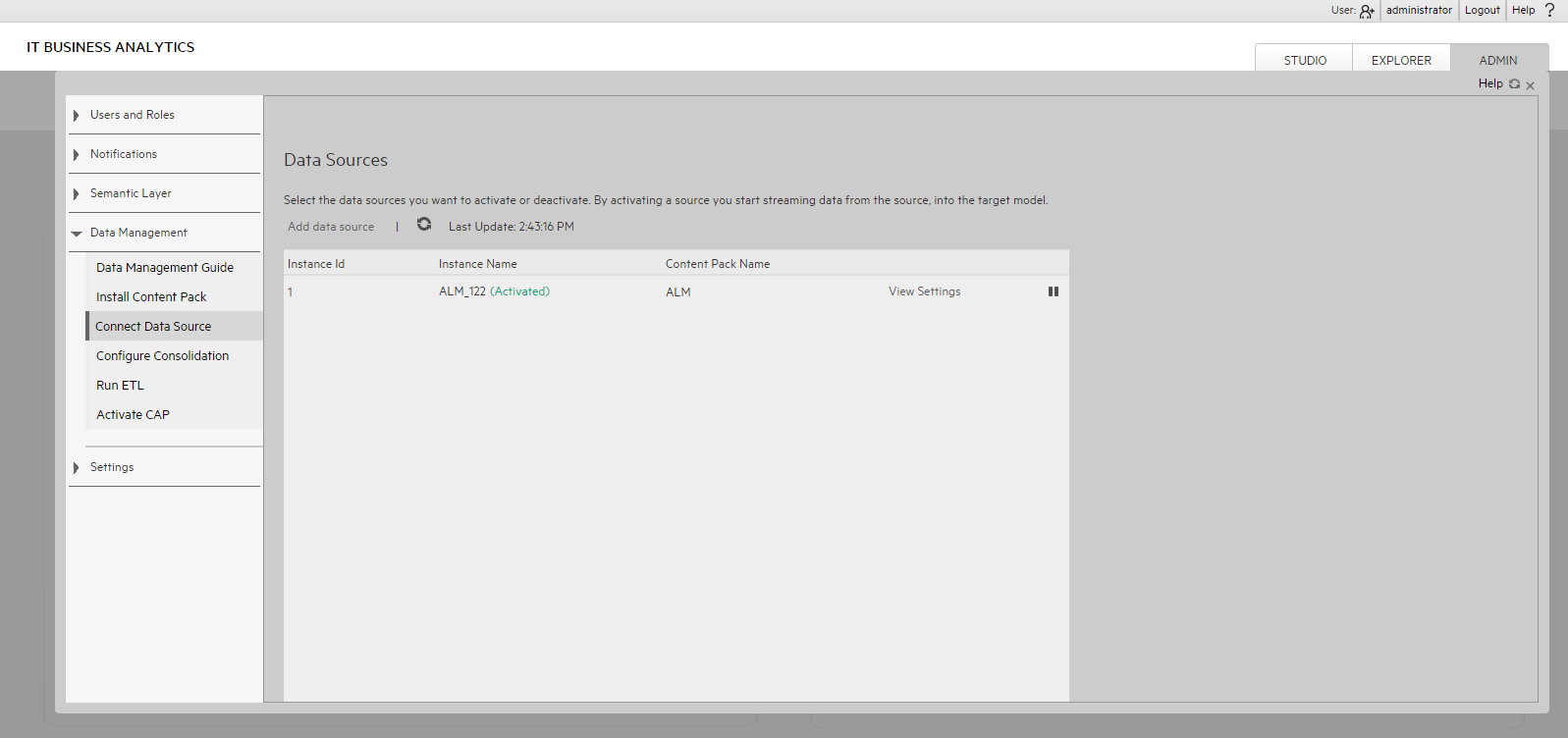
Extraction Mechanism. The extraction is a self-managed web service. The data source connection information is registered to the framework when adding a new data source in ITBA > ADMIN > Data Management > Connect Data Source.
-
Extraction Methodology. The extraction is done using extractors running on the application container of the Data Warehouse. The extractors use various technologies (for example, JDBC, Web Services, data files, and other kinds of HTTP requests) to extract the data from the data source. Each extraction is an isolated job that cannot be affected by other extraction jobs. Each extraction has a unique batch ID. The batch ID is incremental and cannot duplicated even for different Content Pack instances.
-
ETL Source Extract. The first stage of the ETL is the Source Extract. In this phase, the Content Flow Manager performs an HTTP request that activates the relevant extractor.
The DCS extractor extracts the data from the data source into flat files. All Content Packs integrate using DCS, where data is extracted from the data source into .TXT files with a well-defined standard structure.
-
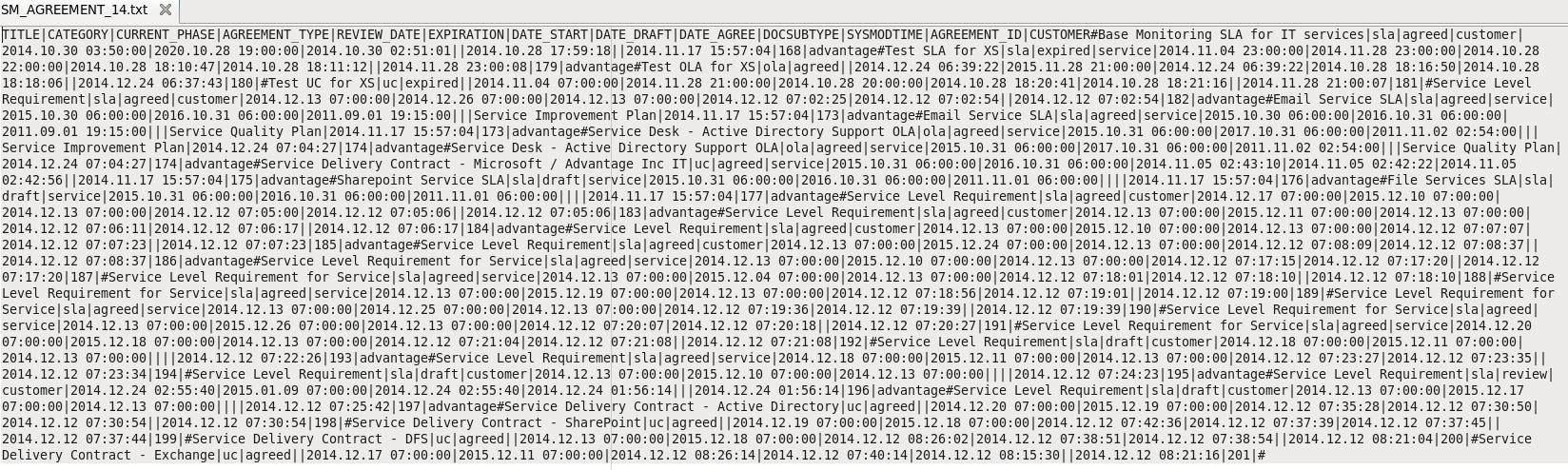
Format of flat files. The first line of a flat file should be the headers of all columns, separated with “|” symbol. The data follows with the columns values separated with a “|” symbol and the lines separated with a “#” symbol.
If a column value includes special characters like “|”, “#” and “\”, it should be escaped by adding a “\” symbol before the special character. The DCS framework has a FlatFileWriter will handle the details of writing the headers and values.
Flat file example:
-
Data sources and Content Packs.
The following data source types are available for each Content Pack:
Content Pack Data source type ALM ALM AM MSSQL, Oracle AWS AWS AWSCW AWSCW Azure GENERIC CSA CSA PPM Oracle SA Oracle SM MSSQL(Non dbdict), Oracle(Non dbdict), MSSQL(dbdict), Oracle(dbdict), DB2(dbdict) CO CO -
Troubleshooting Logs.
- $HPBA_Home/glassfish/glassfish/domains/BTOA/logs/dcs.log: This log describes all of the current activity of the DCS framework as well as the activity of the common utilities and general extractors.
- $HPBA_Home/glassfish/glassfish/domains/BTOA/logs/dcs.extractor.log: This log describes the activity of all the extractors.