



Failover and recovery
The following describes typical failover scenarios and their recovery actions.
Pgpool stops on the standby database server
Verify that the standby database server is healthy:
-
From the primary database server:
# sudo -u postgres psql -h <standby> -p 5432 -c 'select pg_is_in_recovery()'
pg_is_in_recovery
-------------------
t
(1 row)
-
If this query returns "t" as shown above, then all that is required is to restart pgpool from the standby database server:
# systemctl start pgpool.service
-
Confirm pgpool is running properly:
# systemctl status pgpool.service
Pgpool stops on the primary database server
Verify that the primary database server is healthy:
-
From the standby database server:
# sudo -u postgres psql -h <primary> -p 5432 -c 'select pg_is_in_recovery()'
pg_is_in_recovery
-------------------
f
(1 row)
-
If this query returns "f" as shown above, then all that is required is to restart pgpool from the primary database server:
# systemctl start pgpool.service
-
Confirm pgpool is running properly:
# systemctl status pgpool.service
PostgreSQL stops on the standby database server
- First, perform a backup of the primary database server.
- Address the root cause of PostgreSQL's stoppage.
-
From the primary server, run the following command to confirm that connectivity exists with the primary server:
# ssh <standby> service pgpool status
<- should see normal pgpool status output ->
-
From the standby server, restart PostgreSQL:
# systemctl start postgresql-<version>
The placeholder <version> stands for the version of Postgresql.
-
From the primary server, confirm that pgpool has attached to both the primary and standby servers:
# sudo -u postgres psql -h <DB-VIP> -p 9999 -c "show pool_nodes"
The command should return something like this:
node_id | hostname | port | status | lb_weight | role
---------+-----------+------+--------+-----------+---------
0 | <primary> | 5432 | 2 | 0.500000 | primary
1 | <standby> | 5432 | 2 | 0.500000 | standby
The "role" column should contain the appropriate primary/standy value and the status column should be "2" for both nodes.
If the status value of standby is 3, please use the command ‘pcp_attach_node -h <fqdn of the master pgpool> -p 9898 -U postgres -n <node_id>’ to attach it.
-
Confirm replication is active. To do this, run the following command from the primary server:
# sudo -u postgres psql -h <primary> -p 5432 -c 'select sent_location, replay_location from pg_stat_replication'
The command should return something like this:
sent_location | replay_location
---------------+-----------------
7D/90004B0 | 7D/9000478
(1 row)
- Wait 60 seconds, and run the same command. The results should differ.
PostgreSQL stops on the primary database server
Recovery will involve a Service Portal service outage. After recovery, the primary and standby databases will swap roles.
Note In the following steps, "new-primary" refers to the original standby server, which has been promoted. Similarly, "new-standby" refers to the original primary server, which has stopped.
The following diagram illustrates how the system changes when a failover event occurs.
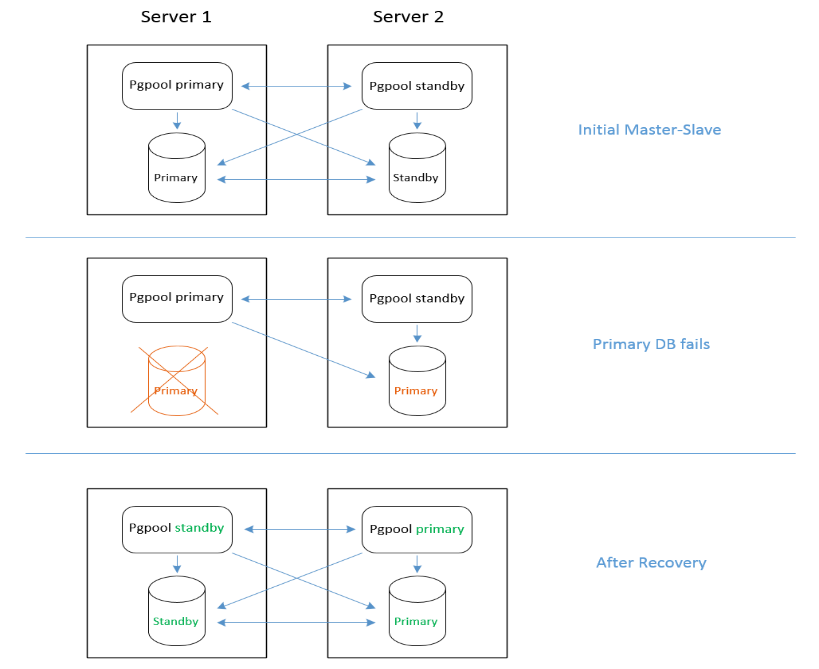
-
On the new-standby, stop pgpool and confirm PostgreSQL is stopped:
# systemctl stop pgpool.service # systemctl status pgpool.service # systemctl status postgresql-9.5
-
Stop Service Portal on all Service Portal nodes:
# propel stop
-
On the new-primary:
-
Stop pgpool and stop postgresql-9.5:
# systemctl stop pgpool.service # systemctl stop postgresql-9.5
-
Edit the access control to allow the connection from the slave:
# vim /var/lib/pgsql/9.5/data/pg_hba.conf host replication <repl_XXXX> <IP>/32 md5
Note <IP> is the new slave IP. <repl_XXXX> is the replication user on the master, you can run the following command to get the replication user name:
# su - postgres -bash-4.2$ psql postgres=# \du
-
Run the following command to edit
postgresql.conf:# vim /var/lib/pgsql/9.5/data/postgresql.conf
Comment the following line:
#hot_standby = 'on'
-
Start postgresql-9.5:
# systemctl start postgresql-9.5
-
-
On the new-master, create a new replication slot:
# su - postgres -bash-4.2$ psql postgres=# SELECT * FROM pg_create_physical_replication_slot('<new replication slot name>'); postgres=# SELECT * FROM pg_replication_slots; postgres=# \q -bash-4.2$ exit # service postgresql-9.5 stop #service postgresql-9.5 start #service postgresql-9.5 status -
On the new-standby, run the following commands to synchronize data from the new-master to the new-standby:
# su - postgres -bash-4.2$ cd /var/lib/pgsql/9.5 -bash-4.2$ mv data/ data.bak/ -bash-4.2$ pg_basebackup -h <new-master IP> -p 5432 -U repl_XXXX -X stream -D /var/lib/pgsql/9.5/data
The default password is 'PASSWORD'
-bash-4.2$ mv data/recovery.done data/recovery.conf -bash-4.2$ vim data/recovery.conf
Change the value of the host in primary_conninfo from the old-master IP address to the new-master IP address. Also change the value of primary_slot_name to the replication slot created in step 4.
primary_slot_name = '<new replication slot name>' -bash-4.2$ vim data/postgresql.conf
Uncomment the line : #hot_standby = 'on'
-bash-4.2$ exit # systemctl start postgresql-9.5
-
Start pgpool on the new-master first, and then start pgpool on the new-standby:
# systemctl start pgpool
-
Check the status of DB nodes and the replication state on new-master:
# sudo -u postgres psql -h <DB-VIP> -p 9999 -c "show pool_nodes" node_id | hostname | port | status | lb_weight | role ---------+---------------+------+--------+-----------+--------- 0 | <new-standby> | 5432 | 3 | 0.500000 | standby 1 | <new-master> | 5432 | 2 | 0.500000 | primary
Attach the new-standby node:
# vim /etc/pgpool-II/pcp.conf
Uncomment the line: # postgres:e8a48653851e28c69d0506508fb27fc5
Note If you have changed the password of user 'postgres', change "e8a48653851e28c69d0506508fb27fc5" to the MD5 value of your new password.
# pcp_attach_node -d 30 <new-master IP> 9898# postgres postgres 0 # sudo -u postgres psql -h <DB-VIP> -p 9999 -c "show pool_nodes" node_id | hostname | port | status | lb_weight | role ---------+---------------+------+--------+-----------+--------- 0 | <new-standby> | 5432 | 2 | 0.500000 | standby 1 | <new-master> | 5432 | 2 | 0.500000 | primary # sudo -u postgres psql -h <new-primary>; -p 5432 -c 'select sent_location, replay_location from pg_stat_replication' sent_location | replay_location ---------------+----------------- 7D/90004B0 | 7D/9000478 (1 row)
-
Restart nginx on LB, start Service Portal on all Service Portal nodes:
# service nginx restart # propel start
Standby server down or unavailable
After addressing the root cause of the server outage, see the "PostgreSQL stops on the standby database server" failover scenario.
Note If the server exited abruptly, pgpool may not initialize properly. See troubleshooting note "Pgpool not attaching to nodes".
Primary server down or unavailable
After addressing the root cause of server outage, see the "Pgpool stops on the primary database server" failover scenario.
Note If the server exited abruptly, pgpool may not initialize properly. See troubleshooting note "Pgpool not attaching to nodes".
Service Portal node down or unavailable
-
After addressing the root cause of server outage, restart Service Portal and OO:
# propel stop # propel start # systemctl restart central.service
-
Verify that the Portal service has initialized properly and restart if necessary:
# systemctl status portal
Load balancer down or unavailable
-
After addressing the root cause of the server outage, restart nginx:
# service nginx restart
If the backup image of the load balancer contains a Service Portal installation, it may be necessary to stop Service Portal and OO:
# propel stop # systemctl restart central.service
-
Verify that no node processes are running:
# ps –ef | grep node