



Overview of distributed Service Portal configuration
There are a minimum of five nodes recommended for distributed Service Portal:
- One load balancer (VIP)
- Two Service Portal application nodes
- Two Service Portal database nodes. You can add additional Service Portal nodes as desired. A DB VIP must also be set up.
The following figure shows a cluster with a Load Balancer node, a master DB node, a slave DB node, and two application nodes.
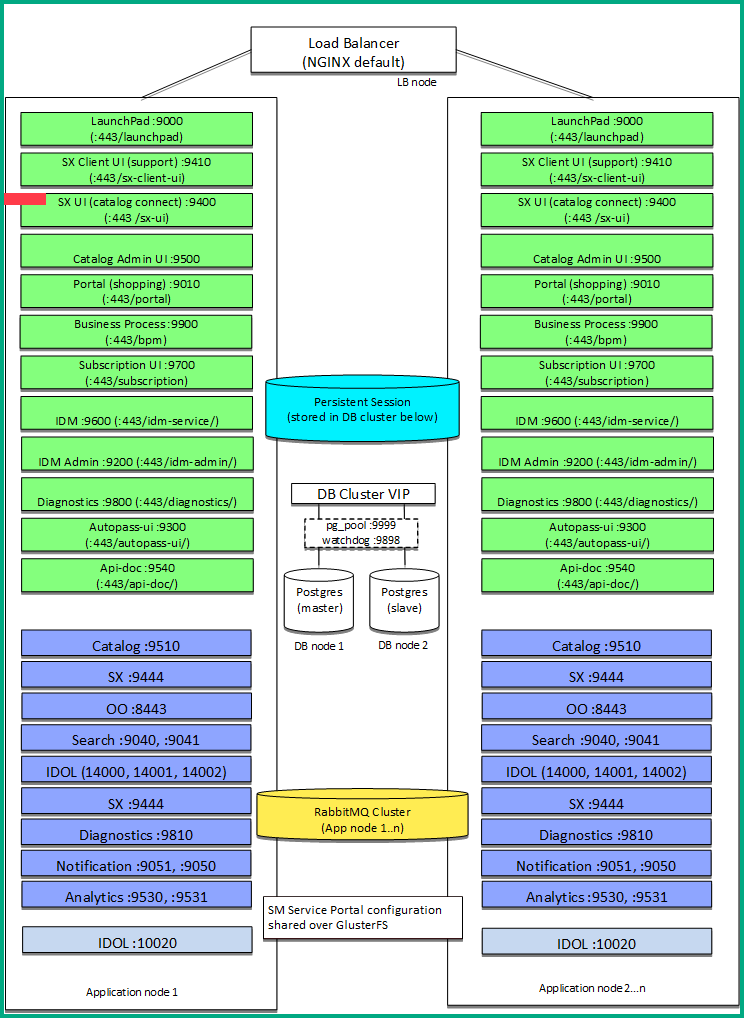
Service Portal services communicate with each other over HTTP (RESTful) APIs. This allows the services to communicate with each other over the load balancer and enables further resilience inside of the Service Portal application stack.
The Service Portal PostgreSQL database will be clustered to provide redundancy. The default setup enables replication between two PostgreSQL DB nodes and provides automatic master-slave failover to the slave if the master goes down. We are not providing the enablement of a High Availability database which would imply scalability beyond two database nodes.
SSL is an important capability of the Service Portal system. Managing and generating signed certificates is important for the security of the system. The configuration implemented in the Distributed Service Portal scripts enables communications to be always encrypted. The default setup ensures that encryption is still enabled, but allows for self-signed certificates. In production systems, HPE recommends using only Certificate Authority-signed and trusted certificates.
The steps described in this section will accomplish the following distributed Service Portal configuration:
- On the Load Balancer node, only NGINX is running. During the distributed Service Portal configuration, this node is used to run the Ansible playbook scripts.
- On the two Service Portal application nodes, all Service Portal application services are running. The PostgreSQL instances should not be running here.
- On the two Service Portal DB nodes, all Service Portal services, OO and IDOL are disabled. These nodes are only used for DB purposes and are clustered using pgpool.
Terminology
The following table explains the common terms that you will find throughout the Service Portal documentation.
| Term | Description |
|---|---|
| Ansible | An Open Source software platform designed to consistently, reliably and securely configure and manage server and similar nodes with minimum overhead. |
| Ansible playbooks | Ansible playbooks leverage YAML and Jinja templates to organize complex Ansible jobs into roles and tasks. For more information, refer to the Ansible documentation. |
| DB VIP | A virtual IP address that does not correspond to an actual physical network interface. It is primarily used by pgpool as a floating IP address. |
| Distributed Service Portal Cluster | A term used to describe a cluster of Service Portal system servers (nodes) configured in such a way that they function as a single logical unit. The cluster provides both the High Availability and Scalability of the Service Portal system. |
| Load balancer | A load balancer acts as a reverse proxy and distributes network or application traffic across a number of servers. Load balancers are used to increase capacity (concurrent users) and the availability of applications. |
| Master and slave databases | PostgreSQL refers to a multiple node database setup as Master/Slave. |
| NGINX | An Open Source high-performance load balancer. The default supported configuration of Distributed Service Portal uses this product. For more information, see the NGINX documentation. |
| OO | HPE Operations Orchestration. Enables enterprise scale IT process automation. This product is used by Service Portal. |
| pgpool | Middleware that supports PostgreSQL to provide connection pooling. |
| PostgreSQL | Open source object oriented relational DBMS. For more information, visit https://www.postgresql.org. |
| Service Portal DB Node - High Availability | If a Service Portal DB node or network route (connection) to a node goes down in a planned or unplanned outage, the Service Portal system is still available to users. If the Master DB node breaks down, a fault is automatically detected and the Slave is automatically promoted to the Master, with no downtime. |
| Service Portal Node - High Availability | When a Service Portal server (node) or network route (or connection) to a node or a service instance goes down in a planned or an unplanned outage, the Service Portal system is still available to users. |
| Service Portal Scalability | The ability to add Service Portal nodes to increase the scale of the Service Portal system. Nodes are typically added to either increase the number of users that can be supported or the volume of transactions that can be processed. |
| RabbitMQ | Open source message-broker software that implements Advanced Message Queuing Protocol (AMQP). For more information, visit https://www.rabbitmq.com. |