



Note The information described in this section does not apply to OMi in an Operations Bridge Suite container deployment. For information on this topic in a container environment, see the Operations Bridge Suite help.
You can improve your system availability and reliability using high availability options that combine multiple servers, external load balancing, and failover procedures.
Implementing a high availability configuration means setting up your OMi servers so that service is continuous despite power outages, machine downtime, and heavy load.
Load balancing and high availability can be implemented in single-server or distributed deployments. You configure load balancing by adding an additional gateway server and high availability by adding a backup data processing server (DPS).
High availability is implemented in two layers:
-
Hardware infrastructure. This layer includes redundant servers, networks, power supplies, and so forth.
-
Application. This layer has two components:
-
Load balancing. Load balancing divides the work load among several computers. As a result, system performance and availability increases.
External load balancing is a software and hardware unit supplied by an outside vendor. This unit must be installed and configured to work with OMi.
-
Failover. Work performed by the data processing server is taken over by a backup server if the primary server or component fails or becomes temporarily unavailable.
Implementation of load balancing and failover is discussed in detail throughout this
-
For troubleshooting information, see High availability troubleshooting.
Note HPE Software Professional Services offers consulting services to assist customers with OMi strategy, planning and deployment. For information, contact an HPE representative.
High Availability Deployments
The following deployments are supported:
- Basic deployment, with separate gateway and data processing servers
- Alternative deployment, where the gateway and the DPS are hosted together on a server
- Distributed High Availability deployment
Basic deployment, with separate gateway and data processing servers
In this setup, there are two or more gateway servers and two separate data processing servers, where one data processing server (DPS) is active and the other is in hot standby mode. Both are connected to a high available database.
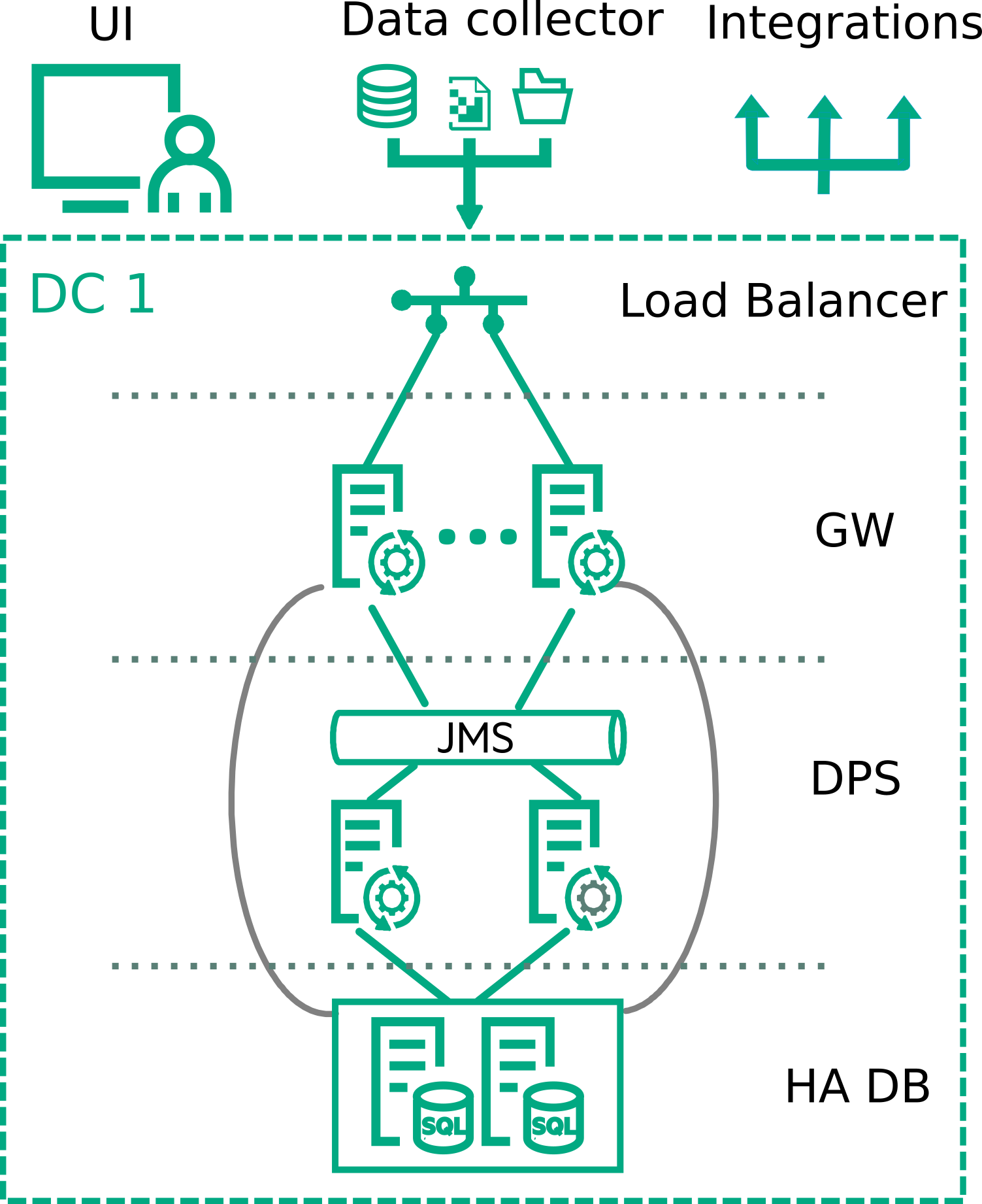
Setting up high availability involves load balancing a set of OMi gateway servers and setting up a failover OMi DPS. Load balancing the OMi gateway servers ensures that there is no single point of failure. If one server in not available there is still at least one server available to process the incoming data and serve the users. Enabling high availability on the DPS causes the High Availability Controller (HAC) to perform an automatic failover if it detects compromised DPS services. If this event occurs, services are assigned to the backup DPS.
Advantages
-
OMi High Availability is the simplest, least expensive solution.
-
The Recovery Point Objective (RPO) should be zero. The system is not accessible only while the primary DPS fails over to the backup DPS. Metrics, events, and topology coming in from data collectors however should be persisted and recoverable once the backup DPS is operational.
-
Recovery Time Objective (RTO) is lower than for OMi Disaster Recovery
Disadvantages
-
We can normally expect an RTO between a few seconds and a minute. It depends on the deployment size and the performance of the infrastructure.
Considerations
-
Automatic DPS failover is not enabled out-of-the-box. To enable automatic detection and fail-over of the OMi Data Processing server’s services, follow the instructions in Configuring Automatic Failover.
-
The Primary DPS and the Failover DPS need to be comparable in terms of hardware, memory, network and storage performance.
-
Gateway servers need to be comparable in terms of hardware, memory, network and storage performance.
-
The first Data Processing Server that is started in OMi deployment will become the primary DPS. The second DPS that is started can be assigned to act as a backup DPS.
-
You can manually reassign DPS services by using the JMX Console (see Reassigning Services with JMX Console).
-
You can enable automatic DPS failover by using the process in Manually Reassigning Services.
Alternative deployment, where the gateway and the DPS are hosted together on a server
In this setup, the gateway and the DPS are hosted together on a single server. The DPS running on the second system is in hot standby mode. Both data processing servers are connected to a high available database.
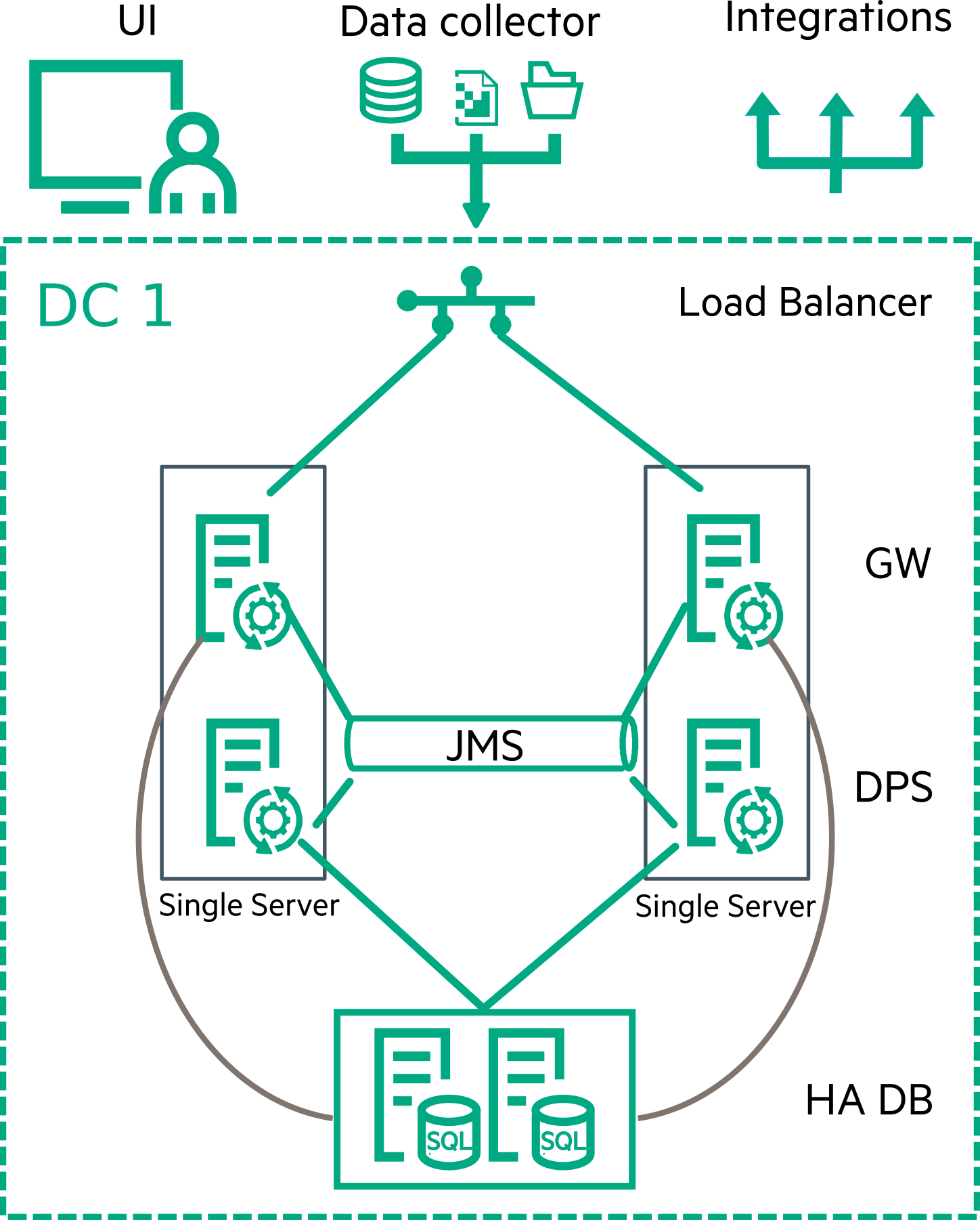
Advantages
-
Fewer servers are needed compared with the solution where each gateway and DPS has its own dedicated server.
-
The Recovery Point Objective (RPO) should be zero. The system is not accessible only while the primary DPS fails over to the backup DPS. Metrics, events, and topology coming in from data collectors however should be persisted and recoverable once the backup DPS is operational.
Disadvantages
-
The system requirements for a server that hosts both, the gateway and DPS are higher.
Considerations
-
Automatic DPS failover is not enabled out-of-the-box. To enable automatic detection and fail-over of the OMi Data Processing server’s services, follow the instructions in Configuring Automatic Failover.
-
The Primary DPS and the Failover DPS need to be comparable in terms of hardware, memory, network and storage performance.
-
Gateway servers need to be comparable in terms of hardware, memory, network and storage performance.
-
The first Data Processing Server that is started in OMi deployment will become the primary DPS. The second DPS that is started can be assigned to act as a backup DPS.
-
To implement this deployment, follow the
-
You can manually reassign DPS services by using the JMX Console (see Reassigning Services with JMX Console).
-
You can enable automatic DPS failover by using the process in Manually Reassigning Services.
Distributed High Availability deployment
In this setup, the gateways and DPS are deployed across two sites (physical locations). On each site, there are two or more gateway servers and two data processing servers. The database acts as a single database clustered across two different physical locations. The single database is also the main difference between disaster recovery, where the databases are separate and distributed high availability.

Setting up Distributed High Availability involves load balancing two sets of OMi gateway servers (up to three servers in each set) and setting up a Primary and a Failover OMi DPS. Each set of gateway servers is deployed to one of two different data centers. The Primary and Failover DPS are divided, with the Primary DPS deployed in the first data center and the Failover DPS deployed to the second data center. Load balancing the OMi gateway servers in each data center ensures that there is no single point of failure. If one server is not available there will still be one or more servers available to process incoming data and serve the users.
Failover is a manual process. You need to reconfigure the links manually on the Global Load Balancer to send the traffic to the failover site and the DPS server needs to be manually failed over to the backup DPS which is not active until each of the high availability process have been started.
There is only one logical database server utilized in OMi High Availability, so no synchronization of events, metrics and topology is needed. Keep in mind that this logical database should have its own high availability system with multiple physical servers.
Advantages
- OMi Distributed High Availability is a reasonably inexpensive solution to maintain.
- OMi Distributed High Availability can be implemented in two different data centers. Because there are strict requirements on the network latency, this is not a full replacement for a Disaster Recovery solution. This can be a good compromise for customers that have two data centers located close to each other with a dedicated high speed fiber connection between them.
- Recovery Point Objective should be close to zero. The system is not accessible while the primary DPS fails over to the backup DPS and the backup DPS’s High Availability services are starting. Metrics, events, and topology coming in from data collectors however should be persistent and recoverable once the backup DPS is operational. A manual process, however is needed to fail over which may impact your recovery point depending on how long it takes to execute this process.
- Recovery Time Objective is lower than OMi Disaster Recovery.
Disadvantages
-
We can normally expect an RTO between a few seconds and a minute. It depends on the deployment size and the performance of the infrastructure.
- Fail over is a manual process. The links need to be reconfigured manually on the Global Load Balancer and the DPS server needs to be manually failed over to the backup DPS which is not active until each of the high availability process have been started.
- OMi Distributed High Availability acts as a single OMi instance rather than two independent OMi instances.
- Requires a distributed OMi database.
- Requires a very fast network connection (less than 20 millisecond network latency, recommended less than 5 millisecond) between data centers. This means that the two data centers must be close enough with a dedicated fiber for the OMi application between each data center (see Considerations).
The considerations for this solution are identical to the ones listed for non-distributed high availability. There are two additional considerations:
-
Ensure that you have a consistent connection with a latency below 20 milliseconds (recommended 5 milliseconds) between the two data centers. Note the following:
- The recommended latency is less than 5 milliseconds. Based on the speed of light over fiber and certain guard bands for network delays, this puts a restriction on the distance between data centers. For details, see http://www.cisco.com/c/en/us/td/docs/solutions/Enterprise/Data_Center/DCI/4-0/EMC/dciEmc/EMC_2.html and search for the phrase “Based on the speed of light”. If your network exceeds the recommended latency, contact HPE support.
- This assumes a dedicated fiber capable of carrying the communication bandwidth for the OMi infrastructure between the two data centers.
- It is important to benchmark the OMi application and OMi database network traffic between the two data centers during normal operations and during failover operations to determine how much fiber needs to be dedicated to the OMi infrastructure.
- Document and practice the manual failover process. If failover is practiced regularly, it becomes a routine operation rather than an operation that is unfamiliar during a stressful time. Regular practice will reduce your Recovery Time Objective.