



After mapping the monitored OMi events to the correct CIs in the RTSM, the next step is to create event type indicators and health indicators.
Incoming events for the various CI types need to be analyzed, so that meaningful event type indicators (ETIs) and health indicators (HIs) can be created.
ETIs are attributes of events (they do not exist as instances in their own right). ETIs are used to categorize incoming events according to the type of occurrence in the managed IT environment. You can configure your monitoring policy in OMi to include an EtiHint. At least one value is required for an ETI, which is used to describe the event occurrence in the environment. An example would be Lost database Connection:Occurred.
Any occurrence on the monitored system of a given type causing an event must be assigned the same ETI. After defining appropriate correlation rules, events are correlated based on the ETIs. The correlation rules relate types of events that can occur on the CI.
HIs determine and display the health of specified aspects of a monitored CI. An HI is used to indicate if a hardware resource is available, and uses one value to represent the normal state of the CI. An example would be ACME System Status:Available. One or more values are used to indicate abnormal states for the CI, such as ACME System Status:Unavailable.
HIs can also indicate the state of a software application, for example, when the load on certain process is normal, high or exceeded. An example of an abnormal state would be Job Queue Length:Too Long for the ACME Work Process CI type.
Only events that provide CI state information can set a health indicator. Health indicators are assigned to a specific configuration item type through the associated ETI.
HIs also provide the data needed by a key performance indicator (KPI) to calculate the availability and performance of monitored resources. See Assigning HIs to KPIs, which shows how to assign HIs from the ACME example to health-based KPIs.
The new CI types for our ACME example environment were introduced in the section Integrate new applications.
For these CI types, there are specific ETIs and HIs. Overview of ETIs and HIs shows the result of an investigation into which ETIs/HIs are important within an ACME environment.
|
CI Type Display Name |
Category |
Name |
Value |
Severity |
Policy |
|---|---|---|---|---|---|
|
|
HI |
|
Available |
Normal |
|
|
|
HI |
|
Unavailable |
Critical |
|
|
|
HI |
|
Available |
Normal |
|
|
|
HI |
|
Unavailable |
Major |
|
|
|
ETI |
|
Occurred |
|
|
|
|
ETI |
|
Occurred |
|
|
|
|
HI |
|
Normal |
Normal |
|
|
|
HI |
|
Too Long |
Major |
|
|
|
ETI |
|
Occurred |
|
Note Health indicators should show the current state of the health of the monitored object. Therefore, events should only set HIs if there is continuous monitoring of the health of the monitored object.
You create HIs and ETIs in the following area of the OMi user interface:
Administration > Service Health > Indicator Definitions
Alternatively, click Indicator Definitions.
Here is an example of how you would create an HI for the CI type ACME System:
-
Open the Indicator Definitions page:
Administration > Service Health > Indicator Definitions
-
In the left pane, click the CI type you want to set an indicator for, in this example, ACME System.
-
In the central pane, click
 New. Alternatively, you can click New in the right pane.
New. Alternatively, you can click New in the right pane.The Create Health Indicator panel opens.
-
In the General section, complete the following information:
-
Enter the display name of the HI to be created, ACME System Status, an identifier, and, optionally, a description of the HI.
Note By default, the Identifier field is filled in automatically. For example, if you enter ACME System Status as the display name for the target Service Manager server, ACME_System_Status is automatically inserted in the Identifier field. Of course, you can specify your own name in the Identifier field if you want to change it from the one suggested automatically.
- The type of indicator that you want to create for this example, Health indicator with associated event type indicator, is selected by default. If you wanted to create an event type indicator, you would select Event type indicator.
-
-
In the States section, you can add indicator states by clicking
New State, or edit an existing state by clicking  Edit.
Edit.In this example, you are adding new indicator states. Therefore, make one state the default state with Normal severity with the value
AVAILABLE, and another state with the severity Critical with the valueUNAVAILABLE.To add the default indicator state with the value
AVAILABLEand with normal severity, do the following:-
Click
New State. -
In the Status field, choose Normal.
-
In the Display name field, enter the display name for the HI indicator state:
AVAILABLE. -
In the Identifier field, enter the system name of the HI indicator state:
AVAILABLE. -
Click
 Add states.
Add states.
Repeat these steps using the required values to add the indicator state with the value
UNAVAILABLEand with critical severity. -
-
Repeat this procedure for other HIs and ETIs you want to create for your CI types.
There are two ways to assign ETIs to an event. Which option you want to use highly depends on the possibility you have to modify the incoming OMi event. We recommend that set ETIs directly in the policy you are using for monitoring. However, it is also possible to assign an ETI to an event with Indicator Mapping Rules.
-
Set the
EtiHintwithin an OMi policyOverview of ETIs and HIs shows a list of the analyzed ETIs and HIs for the ACME monitoring system. The last column gives the information about which OMi policy creates the event. These OMi policies must be enriched with the appropriate
EtiHint.The following graphic shows an example configuration of the
EtiHint.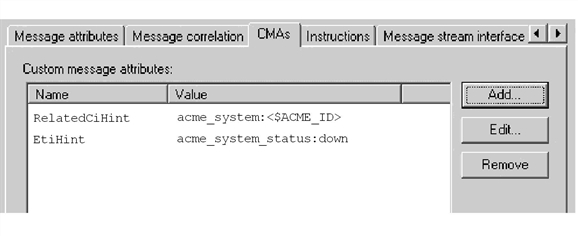
-
Use Indicator Mapping Rules
In the ACME example, all messages are sent using OM policies. Therefore, the CMAs are used to set the ETIs. However, it is also possible to use mapping rules to set ETIs for incoming OM messages.
The following graphic shows an example of a filter configuration for
db connection downrelated messages.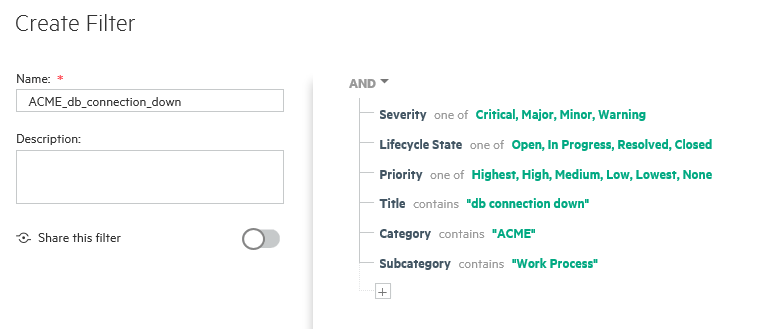
The following graphic illustrates the configuration of the mapping rule itself for the
Lost Database ConnectionETI, using the filter configuration shown above.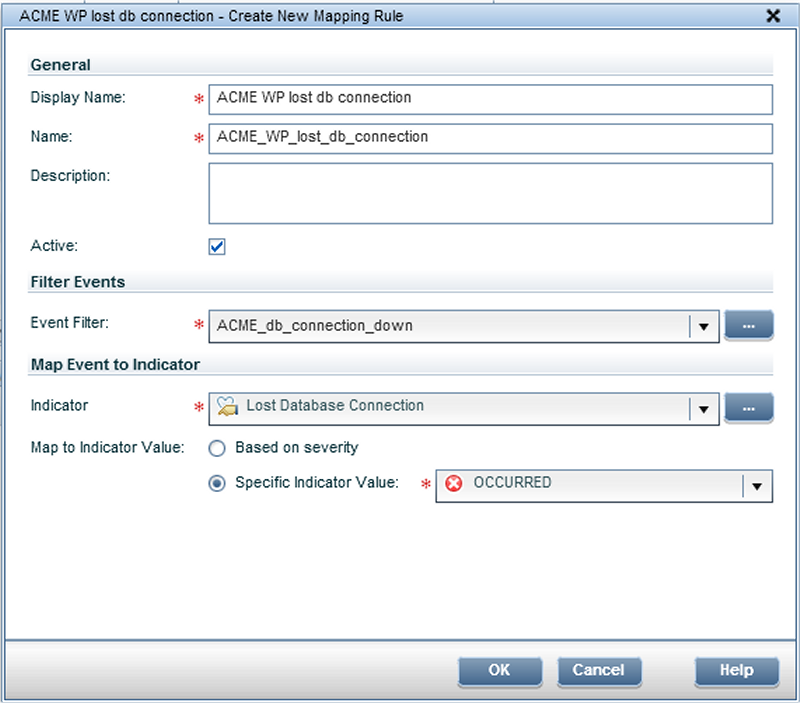
With this mapping rule, you match every incoming message where
Category=ACME,Sub Category=Work ProcessandTitle=db connection lostto the ETILost Database Connectionfor CI typeACME Work Process.
The next step is to assign HIs to KPIs. HIs provide the data that KPIs need to calculate the availability and performance of monitored resources represented by CIs. You assign HIs to KPIs in the following area of OMi:
Administration > Service Health > KPI Assignments
Alternatively, click KPI Assignments.
For details about KPI assignments, see
The HIs from the ACME example, shown in Overview of ETIs and HIs, mostly represent the availability status of the specific CI. Therefore, those HIs are assigned to the Operations Availability KPI.
In this example, the Job Queue Length HI is assigned to the Operations Performance KPI. As a result of this configuration, the Job Queue Length HI is also shown in the Health Perspective for events that are related to CIs of type ACME Work Process.
In the Condition section of the Edit KPI Assignment, you can limit an assignment to a subset of CIs, for example, those monitored by a certain application, or with a specific set of CI attributes.
After you finish assigning HIs to KPIs, click ![]() Apply all rules for the assignment to take effect on existing CIs.
Apply all rules for the assignment to take effect on existing CIs.
In cases where a high level of detail is not required, you may have CIs or CI subtypes that are not modeled in the RTSM. This lowers the work associated with discovering and maintaining those CIs, and simplifies your overall model. However, Service Health will not track individual statuses of unmodeled CIs. Instead, a generic ETI for the node is expressed. You can use the custom message attribute SubCiHint to track statuses of unmodeled CI types. When SubCiHint is set, status is tracked separately for each unmodeled CI individually, enabling Service Health to calculate the overall status as the most critical of all the subCis.
For example, you have CPUs with the RelatedCiHint: cpu:<$acme_cpu_id>:<$acme_nodename>@@<$acme_nodename>and SubCiHint: 0. If the CPUs are modeled in the RTSM, the RelatedCiHint will resolve to the CPU CI. Each CPU can have its own status and all this information can be aggregated on the node using calculation rules in Service Health.
If the CPUs are not modeled in the RTSM, the system will not take into account the distinct statuses of each CPU. In this case, if you get the notification CPU0:bad, followed by CPU1:bad and CPU0:good, Service Health calculates the overall status as "good", even though only one of the CPUs became "good" again. The status will flip between good and bad, only taking into account the most recent status update.
In this example, when SubCiHint is set, status is tracked for each CPU. When CPU0 converts to "good" but CPU1 remains "bad", the ETI on the node remains "bad".
For more information on setting the SubCiHint, see Map events to CIs.