



Overview of the Solr Search Engine
The Solr-based search engine enables the Knowledge Management module to index over 1,200 unique file formats, including the latest versions of Microsoft Office and OpenOffice formats, PDF, HTML/XML, compression, image, audio, etc.
Due to its flexible architecture, the Solr search engine provides scalability and improves indexing performance by supporting the use of multiple index servers. It supports high availability architectures,which include decoupling of search servers from index servers, replication of the search server to multiple servers, and the addition of a load balancer across multiple search servers; in addition, it can provide fail-safe capabilities, such as the creation of a second index server or search server for failover and the ability to switch to a backup server immediately without having to restart or log out and log back in to your Service Manager server.
The following diagram illustrates an example Service Manager Knowledge Management high-level landscape.
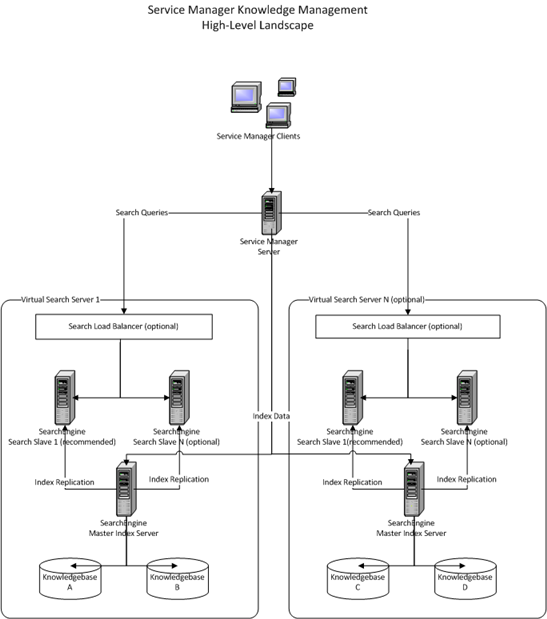
A Knowledge Management search server is composed of three parts: an indexer, a searcher, and a crawler. These server parts are responsible for the following:
- Indexer: Indexes documents into searchable data
- Searcher: Provides results to users' search requests
- Crawler: Indexes the file system and web content
Knowledgebases are assigned to a Knowledge Management search server. If you have a single search server definition, all knowledgebases will be indexed and searched according to that configuration.
When one or more slave servers are defined, all knowledgebases assigned to this virtual search engine will be replicated to each slave. Replication happens when a knowledgebase is re-indexed or the index is updated. Depending on the size of the knowledgebases, they may not be immediately searchable while the replication process is running. If this is a new slave server, you will have to wait for the replication process to finish before you are able to search. Subsequent updates or re-indexes will happen in the background. The slave server will continue to serve search requests on the old knowledgebase until the updated knowledgebase comes on line. It will then automatically begin serving search requests against the new knowledgebase.
Supported Platforms
The search engine runs on multiple platforms, with the same server compatibility as Service Manager.
Language Support
Due to its up-to-date technology, the search engine offers improved Asian language support. Thesaurus maintenance is a lot easier compared to the K2 search engine, because it can now be done through text-based editing. For more information, see Supported Languages for the Solr Search Engine and Create Search Engine Thesaurus Files.
Upgrade
Upgrading from a custom legacy search engine to the cutting edge Solr search engine is invisible to the end-user, and the administrator only needs to assign the new Solr search servers to the existing knowledgebases and re-index. The Search Engine Management has been greatly simplified – there is no more need for mapped drives and complex environment records. For more information, see Upgrading from the K2 Search Engine.
Flexible Installation of File/Web Crawlers
The File/Web Crawlers are no longer chained to the search engine, and can be located separately, with many new website formats supported.