



Deployment Architecture
The combination of NNMi and iSPIs gives you a comprehensive network monitoring solution. While most of the iSPIs are installed on the NNMi management server, NPS—a components of the NNM iSPI Performance for Metrics—and NNM iSPI Performance for Traffic collectors can be installed on separate servers. NPS even enables you to share the computing load across multiple servers by allowing to create a distributed deployment.
This topic covers all the possible installation models of NNMi and iSPIs. The section below elaborates all the models of installing NNMi. The subtopics underneath—Deployment Architecture of NPS and Deployment Architecture of the NNM iSPI Performance for Traffic Collectors— provide details of how NPS and the NNM iSPI Performance for Traffic can be installed on remote servers.
Deployment Architecture of NNMi
You can deploy NNMi in different models—starting with the basic, single-server deployment to more complex, failure-resistant environments built with multiple NNMi management servers. This section provides a list of supported deployment architectures and helps you select an architecture that is ideal for your environment.
This section presents the following topics:
- Single-Server Deployment
- High-Availability Cluster
- NNMi Application Failover Cluster
- Global Network Management

This is the simplest model of deployment. NNMi is installed on a single, standalone server. The NNMi installer is packaged with an embedded database application that can be installed on the same server. You can also use a remote, external Oracle database instead of the embedded database.
While the installation procedure is simple and maintenance is easy, this deployment architecture does not provide any redundancy, and hardware or application failure can disrupt NNMi's course of monitoring. You can choose this model for non-critical environment where occasional disruption does not critically impact your network operation.
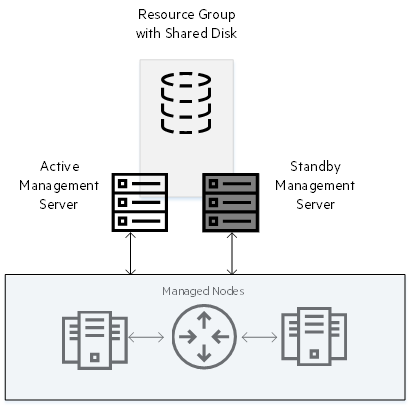
The high-availability (HA) cluster technology enables you to minimize downtime in the event of application failure by creating a cluster of redundant systems. You can install NNMi in an HA cluster to minimize disruptions in your network monitoring activity. NNMi supports the two-node HA cluster environment, which consists of a single active and a single standby management server. Key components of NNMi are installed on a file system that is shared between the two management servers and is referred to as the resource group of the HA cluster. A prerequisite for this deployment is the availability of well-configured HA cluster software on the management servers prior to installing NNMi.
In the event of application failure, NNMi running in an HA cluster can quickly fail over to the standby management server with nearly no disruption in monitoring. Choose this model of deployment when you manage mission critical networks that require nonstop monitoring.
NNMi Application Failover Cluster
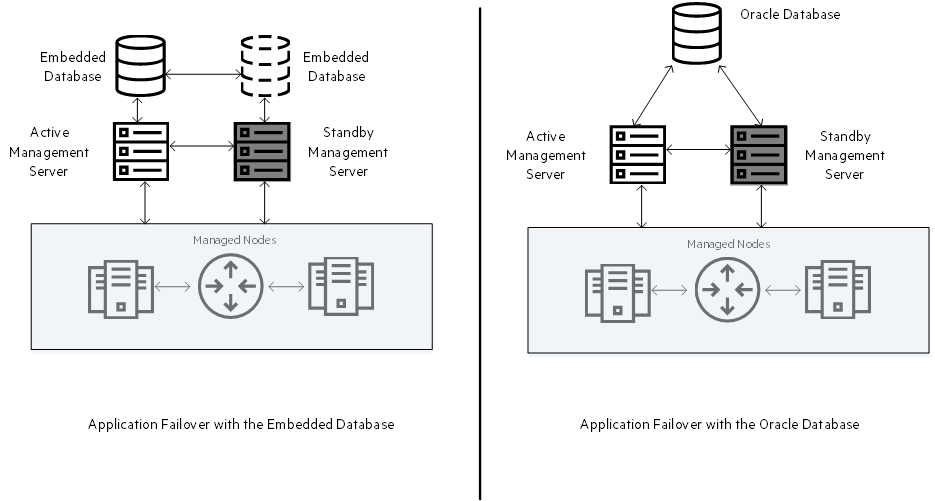
The NNMi application failover cluster is a two-server deployment of NNMi where you can get some benefits of an HA cluster without having to install and configure any HA cluster software. This deployment consists of two NNMi management servers, one active and one standby, and it provides NNMi with the ability to fail over to the standby server in the event of application failure.
The configuration of application failover changes depending on the type of database configured to work with NNMi. When set up to work with the embedded database, NNMi uses a unique instance of the database on each management server and continuously synchronizes the standby database with the active database. When set up to use an external Oracle database, NNMi uses a common, remote database.
| Characteristic | HA Cluster | Application Failover |
|---|---|---|
| Time to fail over | 5 - 30 minutes | 5 - 30 minutes |
| Requirement for additional software | Requires additional HA cluster software prior to installing NNMi | No requirement for additional software |
| Effectiveness of failover | Completely effective | After failover, users need to use the FQDN of the currently active management server to access NNMi. |
| Patching and upgrading | NNMi can be patched and upgraded without dismantling the HA configuration. | NNMi must be taken out of the application failover cluster before applying a patch or upgrading. |
An application failover cluster with the embedded database works differently from the application failover cluster with Oracle.
An application failover cluster with the embedded database uses two databases—one with the active server and the other with the standby server. Both the management servers exchange heartbeat signals to exchange files and to determine failure. The active database synchronizes the standby database and sends database transaction logs to the standby server periodically.
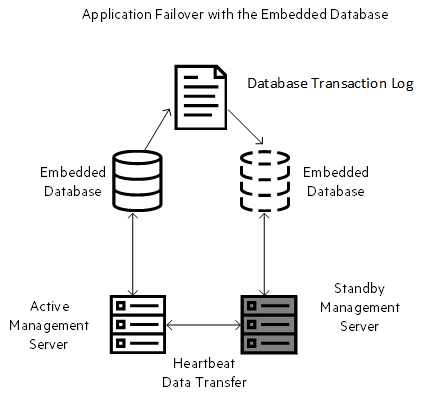
After you start both the active and standby nodes, the standby node detects the active node, requests a database backup from the active node, but does not start NNMi services. This database backup is stored as a single Java-ZIP file. If the standby node already has a ZIP file from a previous cluster-connection, and NNMi finds that the file is already synchronized with the active server, the file is not retransmitted.
Application failover with the Oracle database uses a single Oracle installation, and therefore, does not have the requirement of database synchronization.
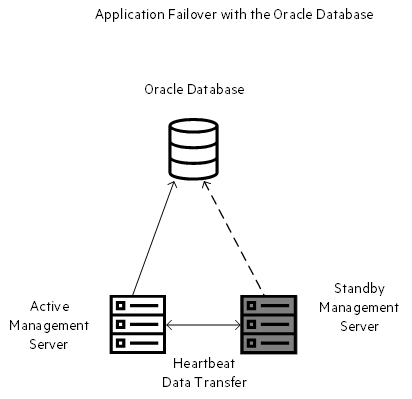
In this scenario too, NNMi uses the heartbeat signal to exchange files between the management servers and to determine server failure.
Global Network Management: Environment with Multiple NNMi Management Servers
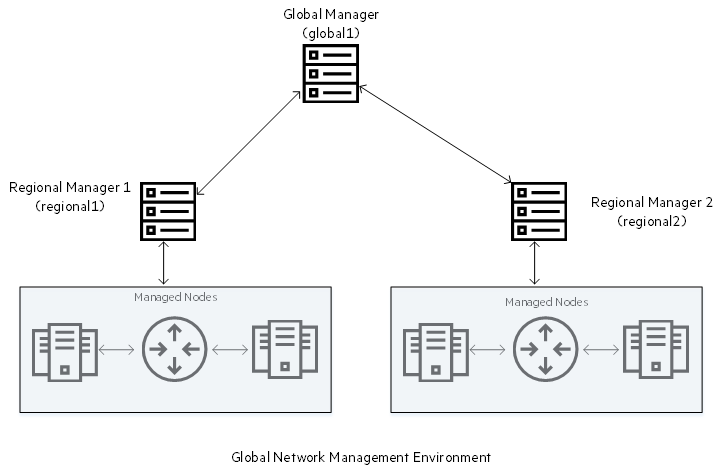
The global network management (GNM) environment of NNMi enables multiple NNMi management servers to work together while managing different geographic areas of the network. You can designate a specific NNMi management server as the global manager to display combined node object data from two or more regional managers. The benefit of a GNM environment is central, big-picture view of your corporate-wide network from the global manager.
Considerations while creating a GNM environment:
- Use the same NNMi version and patch level on the global manager and all regional managers.
- You can configure more than one global manager to communicate with a particular regional manager.
- GNM works with one connection layer. For example,
global1communicating withregional1andglobal1communicating withregional2. Do not configure NNMi for multiple connection levels. For example, do not configureglobal1to communicate withregional1, then configureregional1to communicate withregional2. The global network management feature is not designed for this three layer configuration. - Do not configure two NNMi management servers to communicate both ways with each other. For example, do not configure
global1to communicate withregional1, then configureregional1to communicate withglobal1.
Deployment Architecture of NPS
The Network Performance Server (NPS)—a component of the NNM iSPI Performance for Metrics—provides the infrastructure used with NNMi to analyze the performance characteristics of your network. With the performance data collected by the iSPIs, NPS builds data tables, runs queries in response to user selections, and displays query results in web-based reports that enable you to diagnose and troubleshoot problems in your network environment.
The NNM iSPI Performance for Metrics provides core performance management capability to NNMi by gathering and monitoring the metric data polled by NNMi from different network elements. The combination of NNMi and NNM iSPI Performance enables you monitor the operational performance of your network infrastructure.
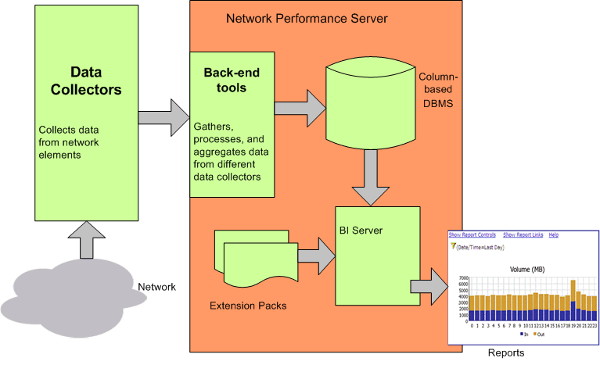
NPS consists of the following components:
-
Column-based DBMS
The column-based DBMS adds data warehousing capability to the NPS solution. The DBMS can store a large amount of data that is gathered from different sources, and enables NPS to compute aggregates from a large number of data points. You can store daily aggregated data for up to 800 days, hourly aggregated data for up to 400 days, and raw/detailed data for up to 400 days. The backup and restore feature enables you to save your data in a compressed, backed-up format. You can use the saved data to restore the database after a system or disk crash.
-
Content Store
The content store is a relational database (RDBMS) used to store report templates, schedules, schedule output, user created report content, and user and group information. It is a much smaller scale than the the column-based DBMS. Data is generally retained indefinitely, except for scheduled output where retention policies are set within the schedule itself. The content store can be backed up and restored.
-
Business Intelligence Server
The Business Intelligence (BI) Server enables you to generate insightful, web-based reports from the data in the DBMS with the help of pre-defined report templates. You can design and save non-default, ad hoc queries and background report schedules. You can publish scheduled reports on the BI Server portal and configure the BI Server to e-mail the scheduled reports.
-
Extension Packs
Extension Packs provide rules and definitions for generating reports from the data. The default, ready-to-use Extension Packs available with NPS, the Self Diagnostics Extension Pack, helps you view reports that indicate the health and performance of various NPS components and processes.
While deploying NPS, you can use one of the three available deployment architecture. The size of your monitoring environment is an important factor in deciding the right deployment architecture. This section of the document provides information about each deployment architecture.
Single-Server Model
You can install NPS on the NNMi management server when you plan to monitor a small-sized environment. The procedure to install NPS (and the NNMi) on the NNMi management server involves running the NNMi on the NNMi management server. See the Support Matrix for information about the sizes of environments that are supported by this same-server installation model where NPS co-exists with NNMi on the same server.
Dedicated Server Model
To achieve greater performance and scale, you can install NPS (and the NNMi) on a standalone, dedicated server. Installing NPS in this model involves running the enablement script on the NNMi management server and running the NNMi installer on a dedicated server. You can opt for this installation model when you want to monitor a large or very large environment.
Distributed Deployment of NPS
You can deploy NPS across a number of systems to take advantage of more computing resources and achieve greater scale. The distributed deployment of NPS enables you to distribute the computing load across multiple systems and designate each system to perform a specific operation determined by the role assigned to the system and provides a way to get past resource constraints on a single server. Distributed environments are best-suited to large scale network monitoring with high scale needs in the area of scheduled report generation, real-time analytics, or custom collection reporting.
Server resources include CPU, memory, and disk I/O. When any one of these resources is fully consumed, you experience performance limitations that can prevent NPS from processing and loading the incoming data fast enough. The following behaviors indicate that NPS is unable to process the data optimally with the available resources:
You can address these problems, to a point, by adjusting how the server memory and CPU resources are allocated with the help of different tuning parameters provided by NPS. If you continue to experience resource bottleneck after tuning NPS, consider spreading NPS processes across multiple servers by creating a distributed deployment of NPS.
You can assign one of the following roles to an NPS system in a distributed deployment:
-
Database Server: The Database Server (DB Server) role is responsible for creating and hosting the NPS database and running database queries. The NNMi installs Sybase IQ on each NPS system. When you assign the DB Server role to a system, NPS starts the Sybase IQ database on the system and creates a shared directory.
In a distributed deployment, you can assign the DB Server role to one or more systems.
You can plan to configure multiple DB Servers if you have a very large environment with high usage of interactive (not scheduled) reports.
Multiple DB Servers are supported only in a Linux environment. Also, you must configure a shared storage system with raw disks with the help of the Storage Area Network (SAN) infrastructure while creating multiple DB Servers.
As a best practice, if you need to configure multiple DB Servers, always start with two servers. Later, based on the performance of the solution, you can add more DB Servers to the environment.
-
User Interface and Business Intelligence Server: The User Interface and Business Intelligence Server (UiBi Server) role is responsible for rendering the available data into reports with the help of templates provided with Extension Packs. When you assign the UiBi Server role to a system, NPS starts the BI server and creates a shared directory.
You can assign the UiBi Server role to only one system.
-
Extract, Transform, and Load Server: The Extract, Transform, and Load Server (ETL Server role) is responsible for performing Extract, Transform, and Load (ETL) operations for the collected metrics.
You can assign the ETL Server role to as many systems as you like. However, each Extension Pack must be enabled on only one ETL Server.
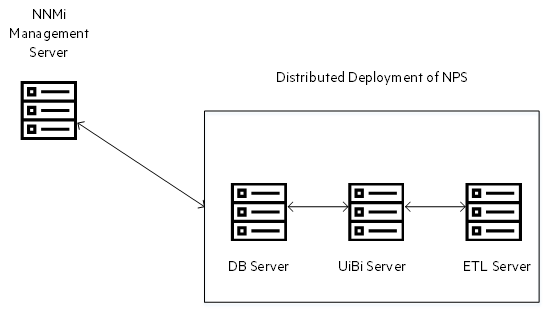
When you configure multiple ETL Servers, you must allocate specific Extension Packs to be processed by each ETL Server. In other words, you must identify which Extension Packs are going to be processed by which ETL Server.
Deployment Architecture of the NNM iSPI Performance for Traffic Collectors
The NNMi consists of two major components—the Leaf Collector and Master Collector. Leaf Collectors collect the IP flow records from different routers and forward the summarized data to the Master Collector. Master Collector processes the summarized data received from the Leaf Collectors and adds the topology context to the IP Flow records. The NNMi Extension for iSPI Performance for Traffic, which is installed on the NNMi management server, provides rules and definitions to generate reports from the data processed by the Master Collector.
